Article by Calum Chalmers, Head of Data Science
Hello and welcome to the inaugural data science blog from Allan Webb. This blog is the first in what will be a series of regular data science blogs that will look at contemporary topics in data science, big data, artificial intelligence (“AI”) and machine learning (“ML”).
In the forthcoming series, we will look at how AI can be applied to real-world use-cases, including:
In this blog I will touch lightly on a range of topics to serve as a taster for the blogs to come.
Defining accurately exactly what AI is and how it relates to “machine learning”, “big data” and “data science” is trickier than people think. In fact, I am going to devote an entire blog to this single topic as there are some key but subtle differences between the terms. Until that blog, for now it is sufficient for our purposes to define AI as:
“AI is the development of intelligent machines or systems capable of performing some sort of intelligent human-like task or behaviour.”
Some everyday successful examples of AI include:

As well as these everyday examples, AI has been successfully developed in a range of areas, including (but not limited to):
A much lauded success story is Google’s AlphaGo (trained using state-of-the-art Monte Carlo simulations, neural networks and reinforcement learning methods) which in 2016 beat the world’s best Go player (Lee Sedol) 4 games to 1. The significance of this AI achievement cannot be understated – Go is a highly complex game with an estimated 10170 possible board positions. Putting that into perspective, physicists estimate there are only 1082 atoms in the observable universe.
Whilst these examples give a basic understanding of what AI is, I think it important to briefly explain what AI is not. Although the inner workings of AI are often shrouded in mystery and is often not very well understood even by some of its practitioners, AI is not magic nor related to potion making nor any other of the dark arts.
What I mean to say is that AI is not the panacea for our data problems. AI is a very powerful tool which when applied properly and correctly to quality data can yield tremendous insights, results and outcomes. However, the key ingredient to any AI or ML model is data, data, data. If data is incomplete, misleading, uncontrolled, false, biased, out-of-date or inaccurate, then no matter how clever or “magical” the AI, it will yield dangerously wrong results and predictions. Simply put, if you put garbage in, you will get garbage out.
However, it should be noted that even when high quality data is available, AI has had some spectacular failures, with some failures being humorous, other failures costly and embarrassing, and others gravely concerning and dangerous. The design and building of quality AI solutions is not a trivial task, and even the experts get it wrong.
Indeed, in a number of situations AI has fallen far short of our expectations, unable to perform a range of human-like tasks that we are able to achieve with ease, such as:
A particularly infamous AI failure was Google’s Flu Trends (“GFT”). When it was developed, Google confidently claimed that by analysing and aggregating the health-related terms from millions of people searching the web when they believe they are going to be ill (e.g. “flu”, “cold” etc.), their model could predict the onset of seasonal influenza two weeks before the US Centre for Disease Control (“CDC”). So confident were Google of GFT that they published their approach in the science journal Nature in February 2009. Clearly the benefit of such a model for saving lives is enormous – there are 250,000 to 500,000 deaths worldwide due to seasonal influenza.
When GFT was first launched in 2008, despite Google needing to quickly update the model in 2009, overall GFT performed reasonably well, at least until around mid-2011.
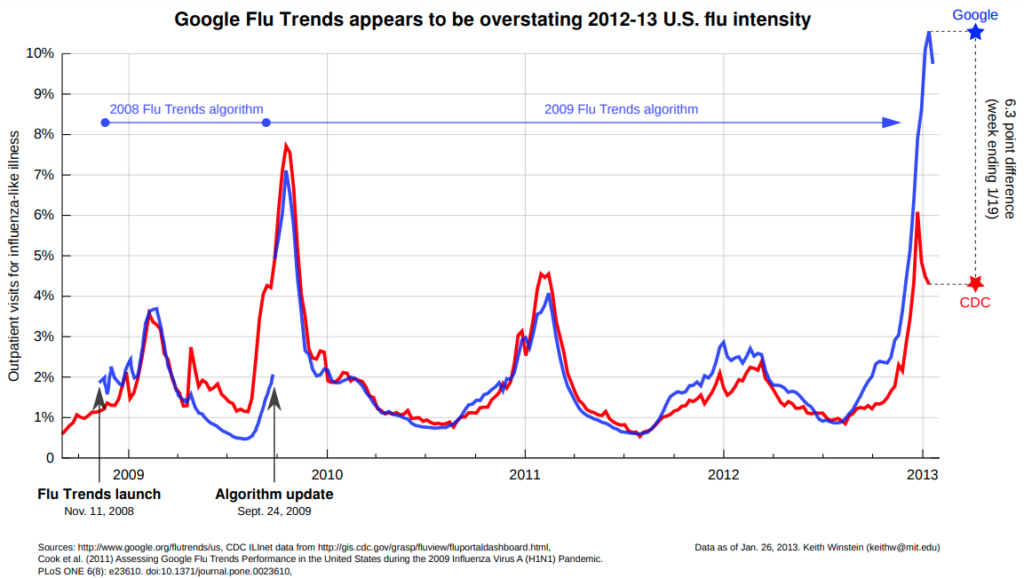
Unfortunately for Google, from mid-2011 GFT performed very poorly, inaccurately predicting the influenza levels in 100 out of 108 weeks and ultimately failing spectacularly in February 2013 when it over-estimated the peak of the flu season by 140%. In the end, Google quietly abandoned the project in 2015.
Whilst AI has certainly had a mix of successes and failures, as I will demonstrate in a future blog, the reasons for the various successes and failures are many and varied. For instance, with some of the AI failures, on occasion it wasn’t the AI per se that failed, but rather the underlying assumptions governing the problem we humans made when developing the AI that were wrong. Conversely, a number of AI developments which have been praised as AI breakthroughs and successes (particularly deep learning for computer vision) have subsequently been shown to be far less accurate than first believed.
Despite previous failures, the scientific method is often based on learning valuable lessons from these failures – the great man himself said, “Failure is success in progress” Albert Einstein.
As for the future for AI, things are certainly looking very promising on a number of fronts. Whilst I personally take market based statistics with a large pinch-of-salt, it is claimed that the global AI market was valued at $62.5 billion in 2020 and is expected to increase at a compound annual growth rate of 40.2% between 2021 and 2028. Whatever the real size of the AI market, it is certainly clear there is huge investment in AI on a truly global scale.
With the significant research and investment into AI by academics, industry and governments, AI does promise to deliver a future with exciting possibilities, from autonomous self-driving transport, to personalised medicine and treatments based on our genetic profiles, to drones delivering our everyday shopping.
However, there is also a significant amount of hype and hubris about what AI will achieve. It doesn’t take long to find blogs and articles on the web making wildly over optimistic predictions, or predictions that are simply nonsense. Some of my favourite ludicrous AI predictions include:

The problem with most predictions (even the sensible predictions) is they are often wildly over-optimistic in terms of the delivery times-scales, or they drastically underestimate the technical and other challenges involved.
As a case in point, given the confident claims made by car manufacturers over the last decade or so, you could be forgiven for thinking that self-driving cars should be a common feature on our roads by now. For example, in a 2017 interview with CNBC, Ford Motor CEO Mark Fields claimed that within 5 years Ford would have developed a self-driving car that would have “no gas pedal, no steering wheel, and the passenger will never need to take control of the vehicle in a predefined area”. Similar overly confident claims about driverless cars have been made by other car manufacturers (Honda, Tesla, Uber etc.) as well as unhelpful claims from the press, such as the Guardian newspaper which confidently predicted in 2015 that from 2020 we would be permanent backseat drivers.
Despite the billions of dollars already invested in driverless car technology, it is fairly obvious that fully automated self-driving cars have not yet materialised for the mass-market. That said, driverless cars will in time undoubtedly be developed, and could even become mainstream assuming continued investment and other necessary requirements are met. We just have to be a little more patient and far more realistic when making predictions about AI.
The latest in vogue AI bandwagon is the so-called AI for Good movement. There are certainly an impressive number of corporations undertaking some sort of AI project with an ethical dimension to them:
These and other ethical projects may well positively impact us and the planet. However, there are also genuine concerns about how ethical or safe AI really is, including:
As an example, consider the rapidly improving and proliferating deepfake technology, i.e. AI generated synthetic videos. Some deepfake videos are obviously intended to be humorous, or helpful, or even educational, and some deepfake videos are even created with the blessing of the subjects involved – consider David Beckham’s 2019 “Malaria Must Die”awareness video in which he apparently speaks 9 languages.
However, in the so-called “post-truth” political environment, deepfake videos pose a seriously threat to truth and the democratic process. For example, a well-timed malicious deepfake video could make false claims about a political candidate, turning voters against them. A particular example is President Donald Trump’s release in 2019 of a basic deepfake video about House Speaker Nancy Pelosi implying that she stammered and slurred her way through a news conference.
Even if the false claims spread by malicious deepfakes are subsequently debunked, the damage may already have been done. The matter is so concerning that it has gained the attention of the Brookings Institution (a non-profit public policy organisation based in Washington DC) which in 2020 published the article “Is seeing still believing? The deepfake challenge to truth in politics”, providing a comprehensive summary of the threats posed by deepfakes, with it being capable of:
“… distorting democratic discourse; manipulating elections; eroding trust in institutions; weakening journalism; exacerbating social divisions; undermining public safety; and inflicting hard-to-repair damage on the reputation of prominent individuals, including elected officials and candidates for office.”
Unfortunately it not clear how best to tackle deepfakes. For example, whilst there have been attempts to legislate against deepfakes (e.g. in 2019, California introduced a Bill designed to prevent the creation or distribution of deepfakes within 60 days of an election), there are many Americans on the other side of the debate who believe such legislation is incompatible with their First Amendment right to free speech. If legislation is not the answer, then perhaps AI could be used to detect and then quickly remove malicious deepfake videos before they cause any real damage. However, according to Professor Hany Farid, a digital-forensics expert at the University of California at Berkeley, researchers working on the detection-side of deepfake technology are simply outgunned as “the number of people working on the video-synthesis side, as opposed to the detector side, is 100 to 1”.
It is of course to be entirely expected that AI will have a significant impact on how defence and warfare is conducted in future. Indeed, according to the MOD’s Data Strategy for Defence report published in September 2021, AI will be used to:
Whilst there are definitely some positive use-cases for AI in defence (even some life preserving benefits), there are concerns about other applications of AI due to the significant threats and potential dangers to our safety. For example, if you listened to the recent fascinating Reith Lectures “Living with Artificial Intelligence” on Radio 4, according to Prof Stuart Russell, AI is being used to develop autonomous drone-like weapon systems designed specifically to target humans. He argues that this application of AI is much more real and dangerous than the Hollywood version of AI achieving some sort of self-awareness and then launching nuclear warfare to eradicate all humankind.
There is much to discuss about AI in defence, so I will leave that, as well as some analysis about the second Reith Lecture “AI in warfare” for another blog.
I hope this blog has been of interest, and I hope you will read some of the future blogs that will appear in this series. In the meantime, if you have any queries or comments, please reach out to me at calum.chalmers@allanwebb.co.uk.

 Bonds Mill Stonehouse Gloucestershire GL10 3RF
Bonds Mill Stonehouse Gloucestershire GL10 3RF
 sales@allanwebb.co.uk
sales@allanwebb.co.uk